Visible Costs, Smarter Chats
Introduction
In our recent update to our custom LLM platform, we introduced a feature that calculates and displays the cost per chat turn. This addition has proven to be powerful for enhancing user understanding of LLM mechanics and promoting more efficient interactions.
The Power of Instant Feedback
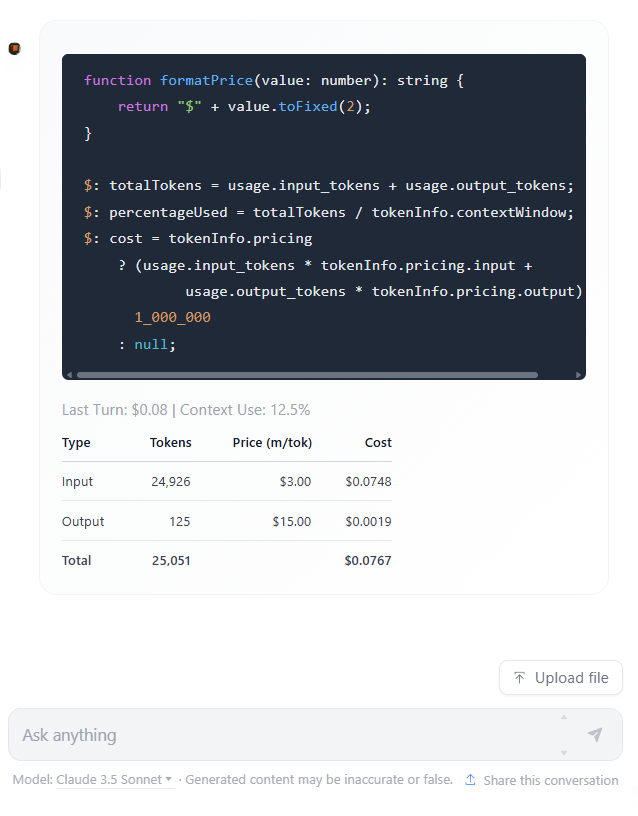
Displaying Chat Turn Cost
By providing immediate cost feedback, users gain invaluable insights into the operation of Large Language Models. This real-time information allows learners to develop an intuitive grasp of several key concepts:
Chat Turn Costs Drive Strategic Prompting: Users are often surprised to learn that input and output costs are priced separately, with output generation being significantly more expensive. For example, a model’s response might cost 4-5 times more than the user’s input. As conversations grow longer and the cumulative cost of both inputs and outputs increases, users naturally adopt more strategic prompting. They learn to craft comprehensive, well-thought-out instructions and questions, minimizing short, trivial exchanges that inflate costs without adding substantial value. This understanding of the cost dynamics encourages users to optimize their interactions for efficiency and effectiveness.
There’s nothing like shooting the breeze with Opus 3 in conversation, then realising it’s $1/turn.
Informed Model Selection: Visible pricing encourages users to match model capabilities with task requirements more precisely. For complex reasoning tasks like product development scenarios or creative writing, users might opt for more powerful (and expensive) models. However, for routine tasks such as text classification or simple translations, users learn that well-crafted prompts on less expensive models can often achieve similar results. This insight leads to selecting the appropriate, most cost-effective model for the job at hand.
graph LR
A["Small Model e.g.\n GPT-4o mini"]
B["Medium Model e.g.\n Claude Sonnet 3.5"]
C["Large Model e.g. \n Claude Opus 3"]
A --"25x cost"--> B
B --"5x cost"--> C
A --"125x cost"--> C
style A fill:#268bd2,stroke-width:1px,color:#fdf6e3
style B fill:#b58900,stroke-width:1px,color:#fdf6e3
style C fill:#6c71c4,stroke-width:1px,color:#fdf6e3Output token scaling costs between GPT-4o mini, Claude Sonnet 3.5 and Claude Opus 3
Mastering Conversation Context: Users learn that LLMs don’t truly converse but instead analyze the entire chat history for each response. This insight, combined with an understanding of the model’s context window limits, becomes crucial for effective interactions. Users discover the importance of crafting the right context for each turn, especially for complex tasks. They learn to balance providing necessary information with managing the growing context, leading to more strategic and effective use of the AI’s capabilities.
Understanding Practical Limits of Context Window: Users gain perspective on the size constraints of even large context windows. For instance, a 200,000 token context (roughly 1 megabyte of text) might seem substantial—equivalent to a large book—but it’s minuscule compared to the model’s overall size. Consider that a 70 billion parameter model (like Llama 2 70B FP8) requires about 70 gigabytes of memory for inference. This 1:70,000 ratio between context and model size is eye-opening. Users learn that even large context windows fill quickly when including detailed instructions, personas, or document contents. This realization underscores the critical importance of crafting focused, relevant contexts for each interaction, especially for complex tasks or when working with external data.
Encouraging Effective AI Stewardship: Visible costs can motivate users to become better “teachers” or “coaches” for AI models. When each interaction has a clear price tag, users are incentivized to provide higher-quality examples, more precise instructions, and carefully curated training data. Just as pricing drives businesses to optimize processes, it could spur users to optimize their guidance to AI. This promotes the development of well-informed users who are better stewards of these powerful tools.
Conclusion
Incorporating chat cost-per-turn information into our LLM training platform has proven to be an invaluable educational tool. It not only enhances user understanding of LLM mechanics but also promotes more efficient and responsible use of AI resources. By making the abstract concrete, we empower users to make informed decisions about their LLM interactions, ultimately leading to more effective and cost-efficient AI utilisation.
For those interested in deepening their understanding of LLM interactions and prompt engineering, we invite you to explore our comprehensive training course. Learn more about optimising your AI interactions and making the most of LLM capabilities.